数据科学基础笔记
PPT - 1
- 数据科学的定义和应用场景
PPT-2
读取数据和保存数据的方法
读 csv 可以用函数 np.loadtxt('xx.csv'),函数全部的参数为 fname, dtype, delimiter, skiprows 分别为文件名,转化后数组的数据类型,分隔符的字符(默认为 none,自动选择),跳过的行数
import numpy as np
data=np.loadtxt('股票.csv',dtype='float',delimiter=',',skiprows=1)
还可以用 genfromtxt,对于空白行、缺省值的处理会更好,遇到注释行自动跳过( # 开头 )具体参数看
利用 genfromtxt 读取数据
第2讲—第二章 数据组织与科学计算20250223, 页面 6
用 np.savetxt 保存数据到文件中:
savetxt(fname, X, fmt='%.18e', delimiter=' ', newline='\n', header='', footer='', comments='#', encoding=None)
fmt :格式字符串,指定数值的格式,如 “%. 2 f”(保留两位小数),默认是 "%. 18 e"(科学计数法)
获取数据后查看数据
ndim 查看维度,dtype 查看数据的类型,type 看的是整个对象的类型
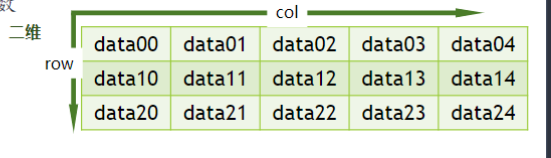
shape 查看数组形状,二维的返回行数和列数(row,col),shape 也可以调整数组的大小, 实则是行列访问的变换
比如:
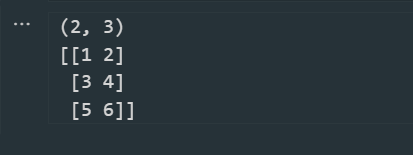
a = np.array([[1,2,3],[4,5,6]])
print (a.shape) //(2,3)
a.shape = (3,2)
print (a)
获取部分列的数据
访问第 row 行,第 col 列:arr[row,col]
访问数组 (row 1 ,col 1)、(row 2, col 2)、……等元素的:arr[[row1,row2,row3],[col1,col2,col3]]
回顾一下 python 的切片方式:Python中切片是左闭右开区间,即包含起始索引但不包含结束索引
NumPy切片的一般语法是:array[start:stop:step, start:stop:step],这里:
- 对于每个维度,可以指定start(起始索引)、stop(结束索引,不包含)和step(步长)
- 如果省略start,则默认从0开始
- 如果省略stop,则默认到数组尾部
- 如果省略step,则默认为1
还有一些高级的切片技巧:
- 负索引表示从尾部计算,如-1表示最后一个元素
- 可以使用省略号
...来表示在其位置选择所有可能的项 - 可以使用布尔数组进行条件筛选
以下面为例 :
data1=data[:,-1] # `:` 表示选取所有行 `-1` 表示选取最后一列(在NumPy中,-1指的是数组的最后一个元素或最后一个维度)
data1=data[:,:2] # 第一个 `:` 表示选取所有行 `:2` 表示选取索引0到1的列(注意Python中切片是左闭右开区间,即包含起始索引但不包含结束索引)
数据归一化
(1) MAX-MIN 最值法
公式原理如下。转换成[0-1]之间的数字
代码实现如下 :
def MinMaxData(data):
min=np.amin(data)
max=np.amax(data)
MinMax=(data-min)/(max-min)# 这一相当于每一个data中的对象都进行了这样的计算
return MinMax
(2)Z-score 方法
公式原理如下。转换成[-1,1]之间的数,且均值为 0,标准差为 1 转换成标准正态分布
公式中,np.mean,标准差为 np.std
代码实现如下:
def z_score_normalize(data):
""" 对数据进行Z-score标准化 参数: data - 需要标准化的数据数组 返回: 标准化后的数据数组 """
# 计算均值
mean = np.mean(data)
# 计算标准差
std = np.std(data)
# 应用Z-score公式:X' = (X - μ) / σ
normalized_data = (data - mean) / std
return normalized_data
数据分析
最大值和最小值
amin 是函数,min 是针对数组的方法。其中 axis=0 计算列最小值,axis=1 计算行最小值
具体参数看
numpy.Amax (a, axis=None, out=None, keepdims=False)
第2讲—第二章 数据组织与科学计算20250223, 页面 12
# 这两行代码功能完全相同
minStock = np.amin(data[:,3]) # 使用np.amin()函数
minStock = data[:,3].min() # 使用.min()方法
均值
np.average 参数具体可见下面。还有加权平均,weights 即为加权数组
Numpy.Average (a, axis=None, weights=None, returned=False)
第2讲—第二章 数据组织与科学计算20250223, 页面 13
加权平均
第2讲—第二章 数据组织与科学计算20250223, 页面 15
标准差、方差
np.var 方差,np.std 标准差
ddof 默认为 0,除数为 n,若为 1,除数为 n-1
# var()用来计算给定数组(或一维数组的某轴向)的样本方差或总体方差(由参数决定)
Numpy.var(a,axis=None,dtype=None,out=None,ddof=0,keepdims=False)
# std()计算样本标准差或总体标准差
Numpy.std(a,axis=None,dtype=None,out=None,ddof=0,keepdims=False)
数据分析
第一个方法直接返回符合条件的元素的值、第二个方法则返回符合条件的元素的位置
Arr[条件语句]
numpy.Where (条件语句)
认识 ndarray
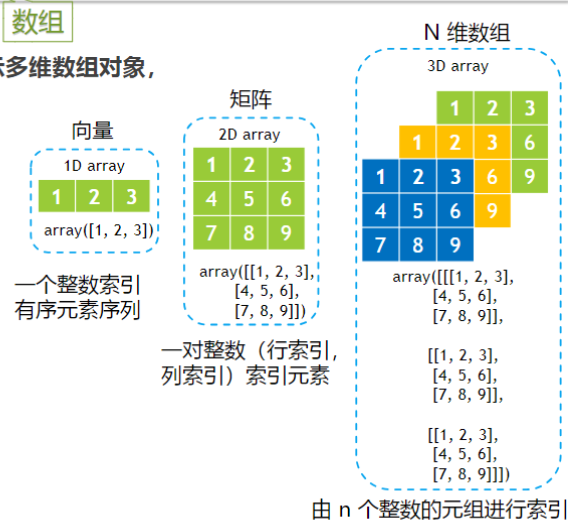
数组初始化与重组
从文件初始化和保存到文件可见 1. 读取数据和保存数据的内容 [[#^a01e1c]]
用array 方法转换列表等为 Numpy 数组
X=numpy.array(object,dtype,shape)
Object :要转化为 Numpy 数组的数据对象,可以是列表、元组或者数组
dtype:转化后数组的数据类型,若不设置则与原数据对象的数据类型保持一致
shape:指定数组的形状,若不设置则与原数据对象的 shape 相同
X:经转换后得到的数组

ones 生成元素为 1 的数组
np.ones(shape,dtype=float)
如,np.ones(6) ,np.ones((2,3),dtype=int)
array([1., 1., 1., 1., 1., 1.]),array ([[1, 1, 1],[1, 1, 1|1, 1, 1],[1, 1, 1]])
zeros 生成元素为 0 的数组,同上
eye 生成单位数组(单位矩阵)
np.eye(5,dtype=int)
np.eye(5,7,dtype=int)
np.eye(5,7,k=1,dtype=int)

K:对角线的偏移量。默认为 0 表示主对角线。正数表示高对角,负数表示低对角
生成随机数数组
# 生成 [0-1) 区间内指定尺寸的均匀分布的随机数组,参数可以是数、元组或列表
np.random.random(size)
# 生成 [0-1) 区间内指定尺寸的均匀分布的随机数组
np.random.rand(d0,d1,...,dn)
# 生成指定范围[low~high)内的均匀分布的数组
np.random.uniform(low,high,size)
# 生成指定范围[low~high)内的随机整数数组
np.random.randint(low,high,size,dtype)
# 生成标准正态分布(均值为0,标准值为1)的随机数组
np.random.standard_normal(size)
# 生成标准正态分布 (loc为均值,scale为标准差,size为形状)
np.random.normal(loc,scale,size)
# 生成标准正态分布(均值为0,标准差为1)的随机数组
np.random.randn(d0,d1,...,dn)
生成固定范围的数组 arange,linspace
np.arrange(start,stop,step) # 左闭右开,[start,stop),step为步长
np.linspace(start,stop,num)# num为需要的数据量,都是闭区间
具体使用参数详见
生成固定范围的数组:arange,linspace
第2讲—第二章 数据组织与科学计算20250223, 页面 31
索引及切片

切片中的范围是左闭右开,即包括起始位置,不包括结束位置。
布尔索引和条件索引
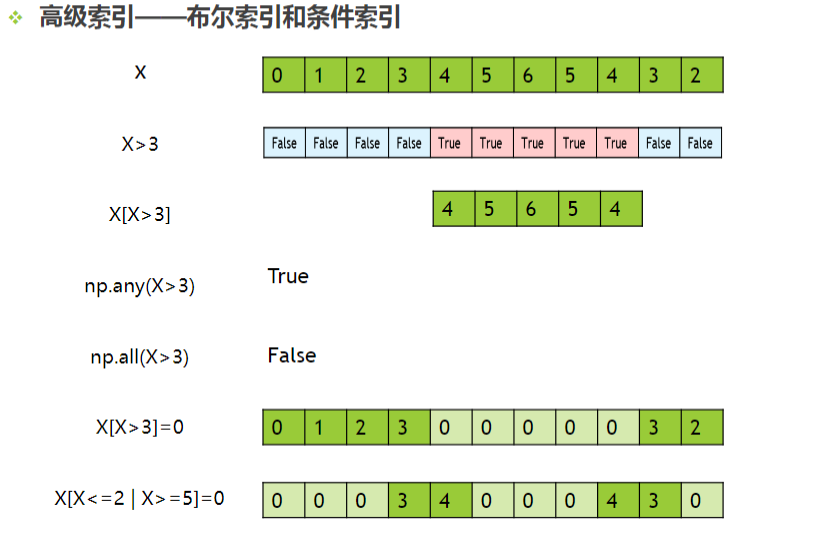
例子:
row=['美的','格力','海尔','西门子']
data=np.array([[3800,1,15],[4000,8,20],[5000,2,30],[4000,20,50]])
bool_list=[False,False,True,False]
print('布尔索引',data[bool_list])
con=data[:,0]<4500 # 条件语令
print('价格小于4500的商品',data[con])
print('价格小于4500的商品',data[data[:,0]<4500])
print('价格小于4000的商品对应的寿命',data[con,2])
插入新行新列
np.insert(被插入数组,位置。插入内容,axis=0/1) # axis=1插入列 axis=0插入行,无axis 将展开输入数组(被插入的数组)
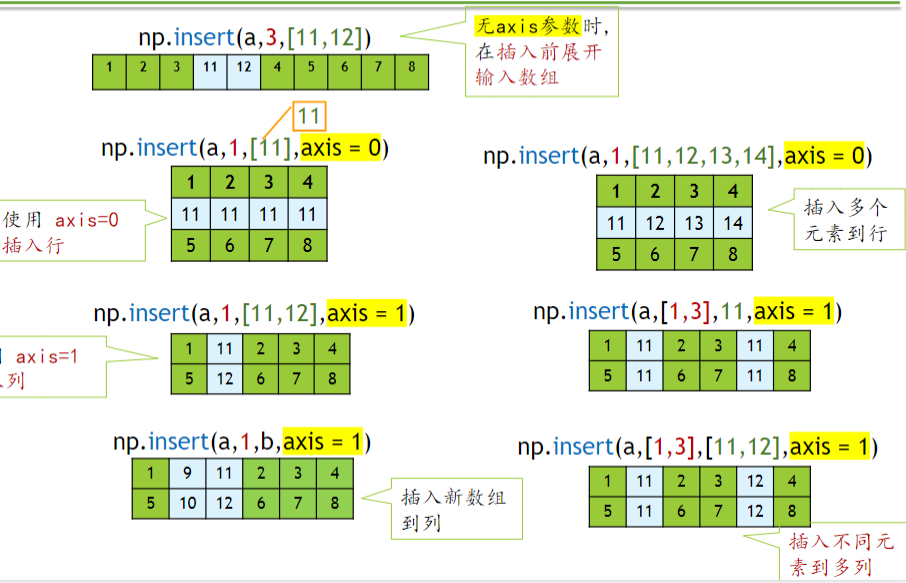
插入新行(列)
第2讲—第二章 数据组织与科学计算20250223, 页面 44
行列交换
#赋值
a[:,2] = a[:,1]
#第0行与第1行交换
a[[0,1],:] = a[[1,0],:]
#第0列与第2列交换
a[:,[0,2]] = a[:,[2,0]]
#本质是赋值
a[:,[0,2]] = a[:,[3,1]]
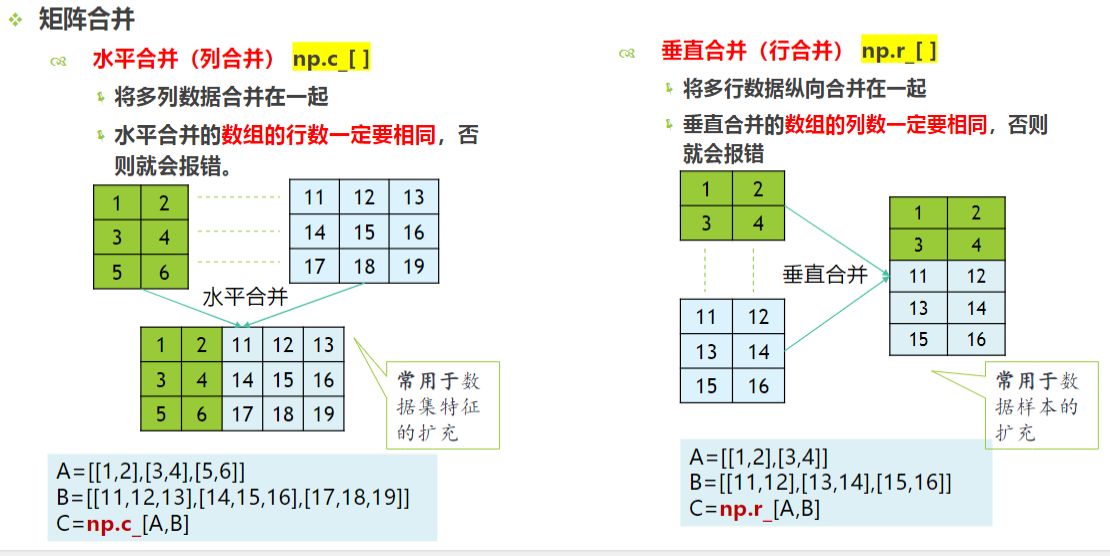
矩阵合并
水平合并 :列合并 np.c_[]
垂直合并:行合并 np.r_[]
矩阵运算
矩阵可以用算术符号进行计算,其中计算逻辑是对应位置的元素进行运算
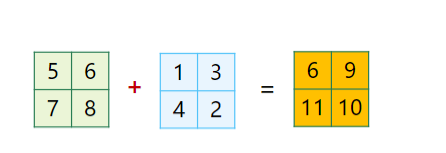
以下为 numpy 提供的运算符号,重点关注 abs,sqrt
print('两次考试的成绩和:',np.add(Score1,Score2))
Score_sub=np.subtract(Score1,Score2)
print('成绩差距以正数显示:',np.abs(Score_sub))
print('对成绩浮动进行开方:',np.sqrt(np.abs(Score_sub)))
print('求浮动值的3次幂',np.power(np.abs(Score_sub),3))
print('成绩商:',np.divide(Score1,Score2))
print('百分制转换成十分制',np.divide(Score1,10))
print('成绩的积:',np.multiply(Score1,Score2))
print('第一次成绩对2取余:',np.mod(Score1,2))
print('两次考试的加权和',np.add(np.multiply(Score1,0.6),np.multiply(Score2,0.4)))
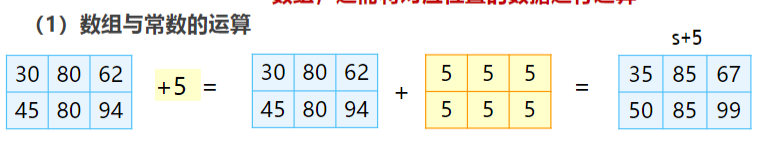
数组和标量的计算:通过广播的形式,扩充成形状相同的两个数组,进而将对应位置的数据进行运算
数组点乘:一维为向量点乘,二维为矩阵的乘积
np.dot()
矩阵转置:a.T, a.transpose()
矩阵求逆:numpy.linalg.inv(a)
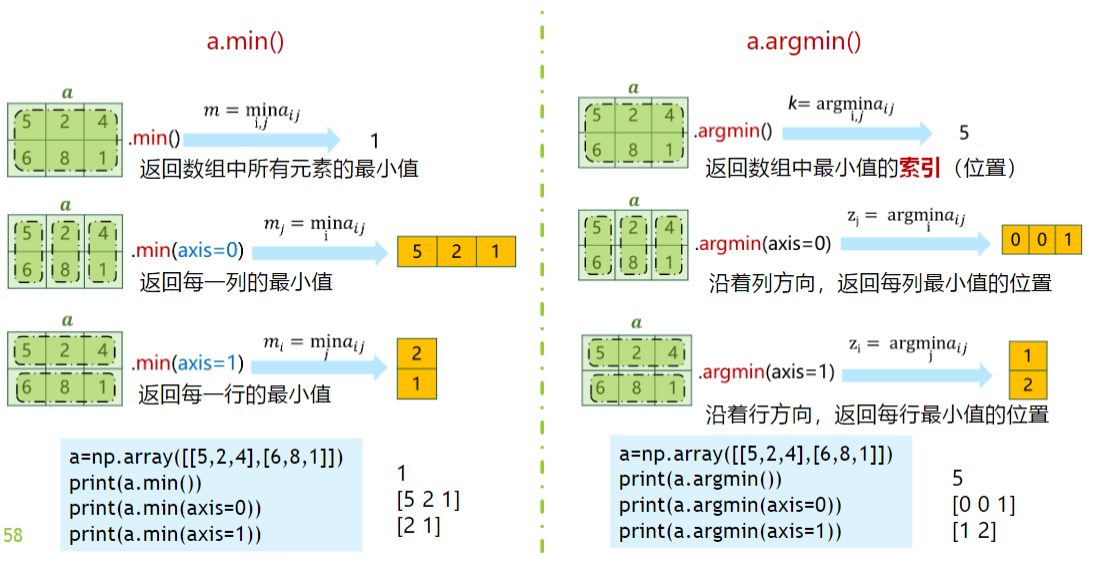
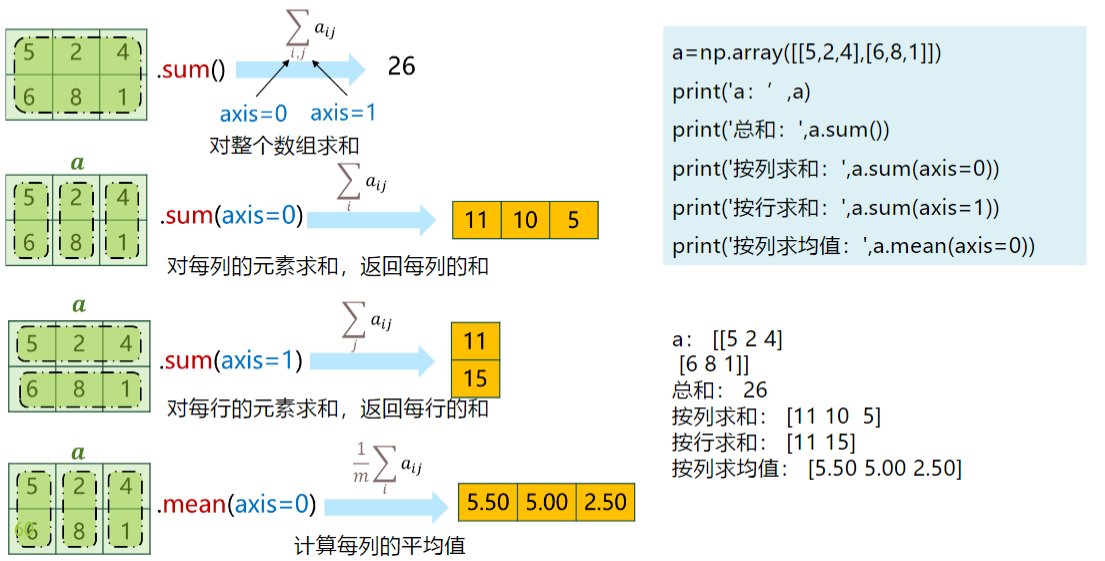
统计函数:axis=1 为行,axis=0 为列
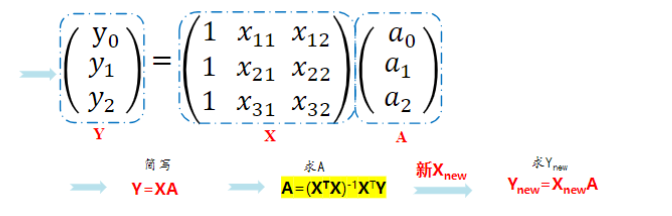
线性回归建模
一元线性回归:
多元线性回归:
求法公式:
Excel 中数据分析的线性回归也可以完成
PPT-3
例题
【例3-1】某超市某一天饮料和牛奶的销售数据如下,要求找出销售额大于200元的商品,并分别统计饮料和牛奶的销售额。
例 3.1 DataFrame 数据访问
举例:根据数据字典: books=
快餐数据集的查询与过滤
引例病人心率数据集
案例:电影票房数据预处理
房价的相关因素
案例 1:电影票房数据统计分析
案例 2: 拍牌数据集的整理与统计分
案例 3:音乐专辑统计分析
Pandas 数据结构
Series 其实就是带标签的一维数组
Series 由两个数组组成,一个是 value(值),index(索引)。
同一个 series 只能存储一种类型的数据
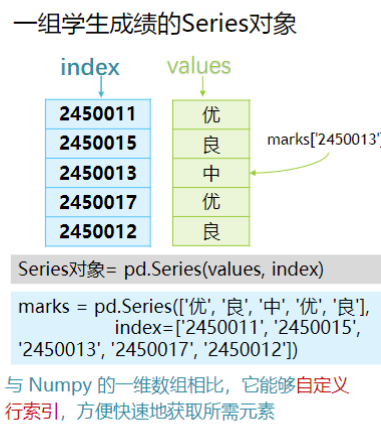
创建 series 对象:
# 直接创建
marks=pd.series(['a','b'],index=['1','2'])
# 字典创建
marks=pd.series({'1':'a','2':'b'})
# 用numpy数组创建
data=np.array(['a','b'])
index=np.array(['1','2'])
marks=pd.series(data,index)
Series 的对象属性:
marks.index: 索引
marks.values:值数组
marks.dtype:数据类型
marks.name:对象的语义描述
Series 对象访问:
访问单个值: Series[元素位置] 或 Series[' index ']:例如 marks[1], marks['2252137']
访问多个值:Series元素位置1,元素位置2,... 或 Series‘index1’,’index2’ :例如 marks[[1,3]], marks[['2450011', '2450017']], marks[1:3] (切片用法,实则是 1 和 2 的元素)
条件查询:
Series[条件语句] 例如:marks[marks=='良']
DataFrame 二维表格
具有行、列两个轴向的索引
每个 DataFrame 对象由三部分组成: 行索引 index、列标签 columns 和值 values
创建 DataFrame 对象
# 用列表创建
data=[['张海','交通工程','男',90],['段霞','金融学', '女',88], ['敬卫华','土木工程', '男',91],['李明','交通工程', '男',54], ['王丹','金融学', '女',67]] index = ['2450001', '2450002', '2450003', '2450004', '2450005']
column = ['姓名','专业','性别','成绩']
students = DataFrame(data,index=index,columns=column)
#用字典生成,这样就不用columns,只需要data和index
stu_dic2=pd.DataFrame({'姓名':['张海','段霞','敬卫华','李明','王丹'], '专业':['交通工程','金融学','土木工程','交通工程','金融学'], '性别':['男','女','男','男','女'], '成绩':[90,88,91,54,67]}, index = ['2450001', '2450002', '2450003', '2450004', '2450005'])
# 第二种用字典生成的方法
lst=[{'姓名':'张海','专业':'交通工程','性别':'男','成绩':90}, {'姓名':'段霞','专业':'金融学','性别':'女','成绩':88}, {'姓名':'敬卫华','专业':'土木工程','性别':'男','成绩':91}, {'姓名':'李明','专业':'交通工程','性别':'男','成绩':54}, {'姓名':'王丹','专业':'金融学','性别':'女','成绩':67}]
index = ['1850001','1850002','1850003','1850004','1850005’] # 根据key自动生成
columns students = DataFrame(data=lst,index=index)
# 利用numpy的array实现
import numpy as np
import pandas as pd
ndarray_data = np.array([['张海','交通工程','男',90],['段霞','金融学', '女',88],['敬卫华','土木工程', '男',91],['李明','交通工程', '男',54], ['王丹','金融学', '女',67]]) index = ['2450001', '2450002', '2450003', '2450004', '2450005'] column=['姓名','专业','性别','成绩’]
df = pd.DataFrame(ndarray_data,columns=column)
查看 DataFrame 对象内容属性
看某一列,就用这一列的 dtype 查看如:students['成绩'].dtype
查看所有列的数据类型用 types
index、columns、values 获取索引、值
shape 获取形状
Dataframe 对象访问
看这个链接
- DataFrame 数据选择
第三章 数据统计分析_20250323, 页面 25
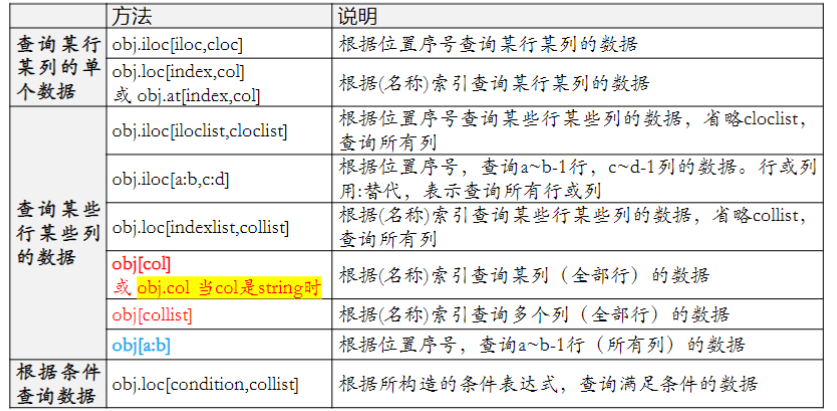
选取列:DataFrame['列名'] 或者 DataFrame[['列名1','列名2',]]
选取行:DataFrame.loc['行标签','列标签'], DataFrame.iloc['行序号','列序号']
选取单个值:DataFrame[column][index] 先列后行,或者用上面那个方式,也是唯一的
条件查询:df.loc[条件表达式,列名列表] 如下:
#查询成绩大于等于90分的学生的姓名、成绩
students.loc[students['成绩']>=90,['姓名','成绩']]
数据修改:对于 Series 对象和 DataFrame 对象,在选取了数据之后,就可以对选择的数据进行修改。
#将DataFrame对象students中第2个学生的成绩修改为85分
students.iloc[1,-1]=85
#将DataFrame对象students中“交通工程”专业修改为“交通类”
students.loc[students.专业=='交通工程','专业']='交通类
数据删除:利用 drop() 方法,要删除一个或多个数据,只需用一个索引数组或列表即可。drop 方法不删除原始对象的数据,而是根据删除后的数据生成新对象若要用新对象替换原对象,使用 drop 方法时,设置参数 inplace=True
#删除Series对象marks中学号为“24500013”,“2450015”的学生成绩
marks.drop(['2450013','2450015'],inplace=True)
#删除DataFrame对象students中学号为“2450003”和“2450005”的学生行记录
students.drop(['2450003','2450005'],inplace=True)
#删除DataFrame对象students中的“性别”列:
students.drop('性别',axis=1,inplace=True)
DataFrame 对象的 drop 方法,用参数 axis 指明按行或列删除数据。Axis=0,删除数据的行,axis=1,删除数据的列。默认 axis=0
添加数据:
Series 对象可以直接添加数据、 DataFrame 对象可以添加新列
# 在marks中添加学号为“2450010”的学生
marks['2450010']="及格"
# 给students添加“年龄”列
students['年龄']=[17,18,17]
算数运算与数据对齐
加法运算
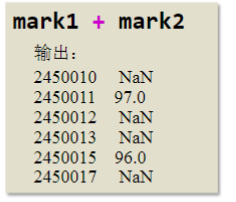
mark1=Series([90,88,78,95,80], index=['2450011', '2450015', '2450013', '2450017', '2450012']) mark2=Series([5,7,8], index=['2450010','2450011','2450015'])
mark1+mark2
Series 对象相加时,会自动进行数据对齐操作。 • 在重叠的索引处,对应值相加; • 在不重叠的索引处,使用 NaN 进行填充。 • NaN(Not a number):代表缺失或者无效值,特殊的 float 类型
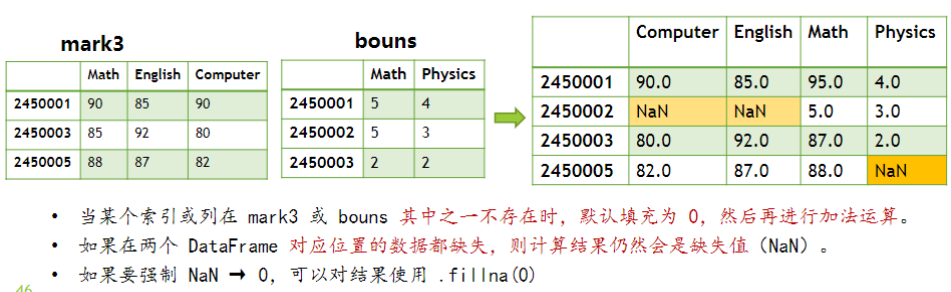
两个 DataFrame 之间进行运算时
• 先进行形状的扩充 • 然后对应位置上的元素进行运算 • 注意:任何数与 NaN 进行运算都是 NaN

用对象的 add、sub、mul、div 方法,进行算术运算
使用这些方法的 fill_value 参数,在算术运算时指定用于填充的值。
例如:mark 3.Add (bouns, fill_value=0)
与标量的运算 +、-、*、/
对象的每个元素均与标量运算
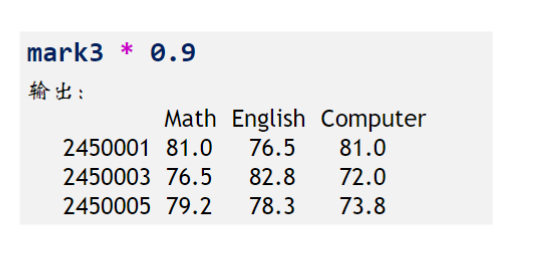
DataFrame 与 series 运算
以广播的形式:具体细节如下:用对象的算术运算方法时,通过 axis 参数指定广播方向。若 axis=0 (或'index' ),按照行索引对齐,在列上广播;若 axis=1 (或'columns'),按照列名称对齐,在行上广播。Axis 默认为 1。
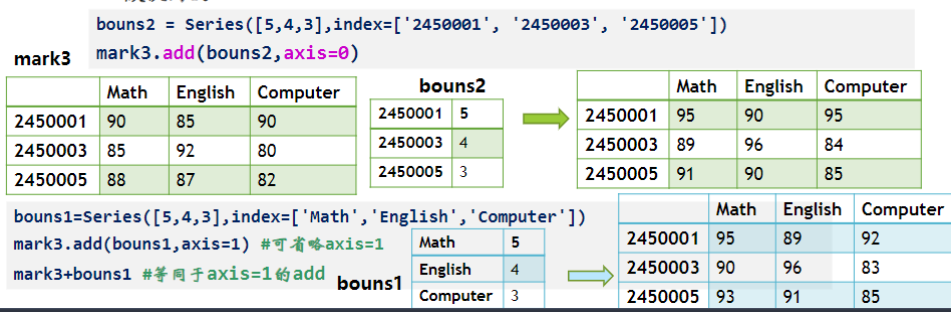
重建与更换索引
df.reindex(index=[]) 利用 reindex 重新指定索引,会创造一个新对象,如果要代替原来的,采用 inplace=Ture
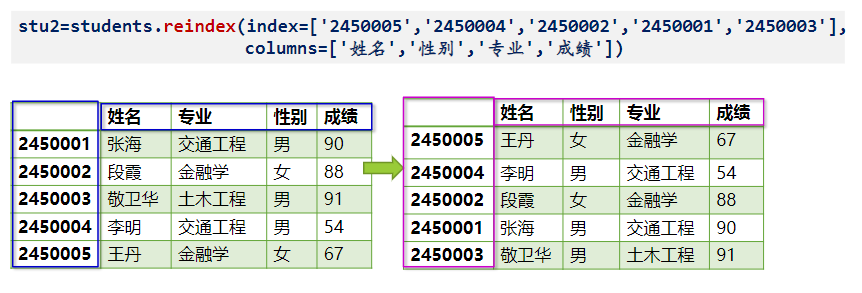
df.rename() 可以重新指定索引(index)和列名(columns),同样会创造一个新对象。
students.rename(columns={'姓名':'学生姓名','成绩':'学生成绩'})
df.set_index(列名) 可以用新的列作为索引,同样会创造一个新的对象
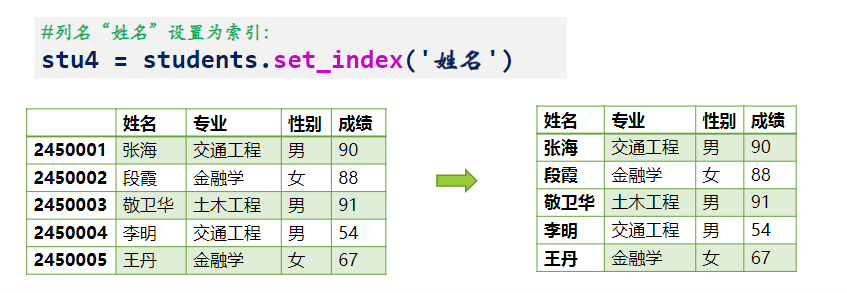
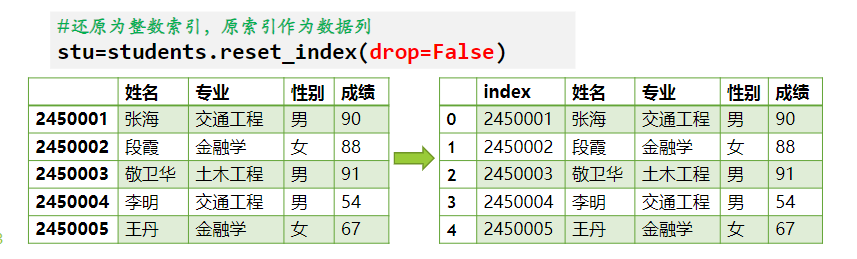
df.reset_index(drop=False) 还原为整形索引,之前的索引如果 drop=False 不删除,反之删除。
其他常用操作
唯一值:
df。unique() Series 对象,或者 DataFrame 中某列的唯一值数组,输出的是值
df。nunique() 统计某列不同值的个数,输出的是数量
值计数:
df.value_count() 计算 dataframe 中某列中每个值出现的频率
value_counts(sort=True,ascending=False,normalize=False,bins=None,dropna=True)
成员资格:
df。isin 来判断 DataFrame 对象列的成员资格,返回一个布尔值的 Series 对象
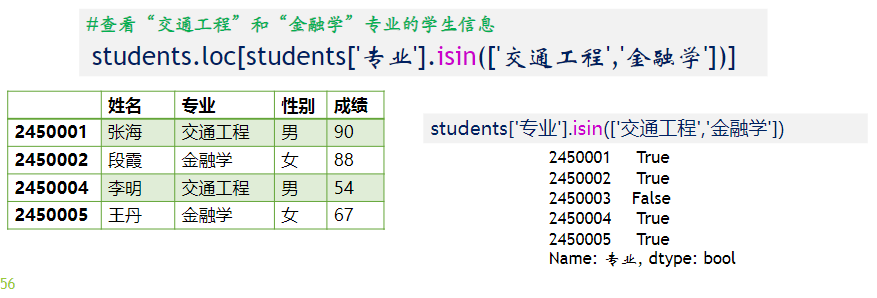
数据加载与保存
加载 CSV/TXT 文件
pd.read_csv 读取以“,”为分隔符的 csv 文件,返回 DataFrame 对象
pd。read_table 读取以"/t"为分隔符的文本文件,返回 DataFrame 对象
具体参数详见
- 加载 CSV/TXT 格式文件
第三章 数据统计分析_20250323, 页面 56
header 设置表头为第几行,也可以用 names 参数为每列指定列名
index_col 指定某一列为索引,usecols 读取指定的几列
encoding 是编码,一般是 gbk,utf-8,ANSI 等
查看导入的数据
data.head() #查看前5行
data.head(2) #查看前2行
data.tail() #查看最后几行数据,默认为后5行
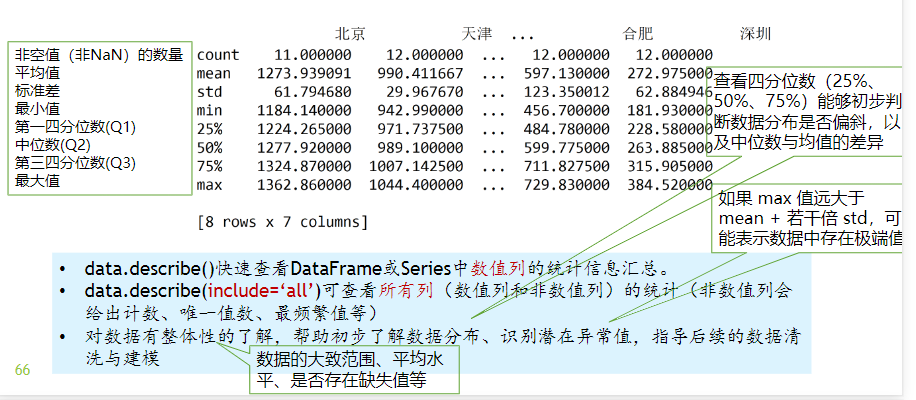
print(data.describe()) #查看整体数值列的各项统计数据
大数据集的处理
- 加载数据集到相同大小的区块中(静态分块,块大小由chunksize固定设置) • pd.read_csv() 提供chunksize参数,用于指定每次读取多少行数据 • 对返回的可迭代对象进行遍历,可一次处理一小块数据
- 动态决定每个区块的大小 • 动态决定时,首先需要将read_csv函数的参数iterator设置为True,返回一个迭代器(而不是DataFrame) • 使用get_chunk(n)方法,手动获取下一块数据,其中n设置为想要读取的行数
#读取文件的前5行并显示
data_iterator=pd.read_csv(r'pop.csv', header=3,skiprows=[4], iterator=True,encoding="gbk")
piece=data_iterator.get_chunk(5)
保存数据:
df.to_csv() 将 dataframe 对象存储到 CSV 文件,参数可见
将 DataFrame 对象保存到 CSV 文件
第三章 数据统计分析_20250323, 页面 67
读取 Excel 数据:
pd.read_excel() 从 excel 中读取文件数据转成 DataFrame 对象
data2=pd.read_excel(r"pop.xlsx", sheet_name='Sheet1',header=3,skiprows=[4]) data2.head()
数据预处理
数据合并
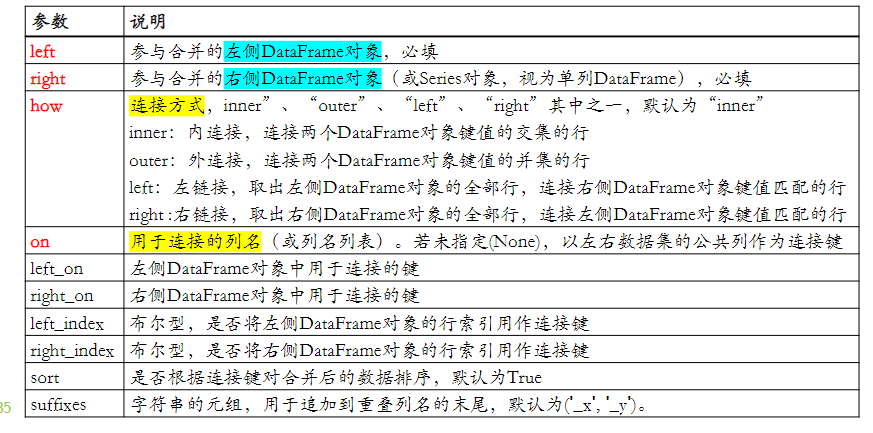
Pandas 提供了三种不同的数据合并方式:
① pd.merge () 函数——类似 SQL 的 join 以数据库连接方式合并数据,可根据一个或多个键,将不同 DataFrame 对象的行进行匹配合并
② pd.concat () 函数——按行或列拼接将多个 DataFrame 沿着行或列进行连接,类似于沿着一条轴,将多张表上下堆叠或左右拼接
③ df. combine_first () 方法——补充缺失值将两个 DataFrame 合并,以第一个 DataFrame 为主,如果第一个 DataFrame 中某些位置是缺失值(NaN),就用第二个 DataFrame 对应位置的值进行填充
数据库方式合并
pd.merge(left,right,how='inner',on=None,… )
轴向堆叠数据
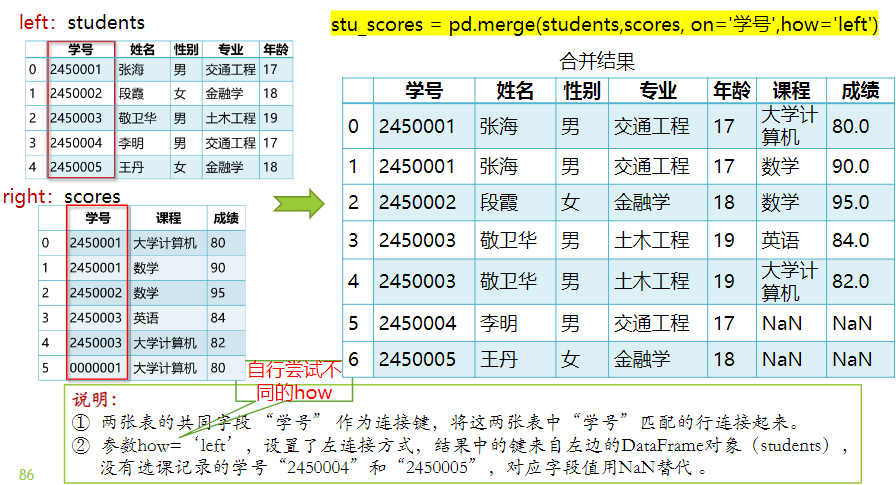
colnames=['学号','姓名','性别','专业','成绩'] data1=[['2450001','张海','男','交通工程',90], ['2450002','段霞','女','金融学',88], ['2450003','敬卫华','男','土木工程',91]]
data2= [['2450004','李明','男','交通工程',54], ['2450005','王丹','女','金融学',67]]
group1=DataFrame(data1,columns=colnames)
group2=DataFrame(data2,columns=colnames)
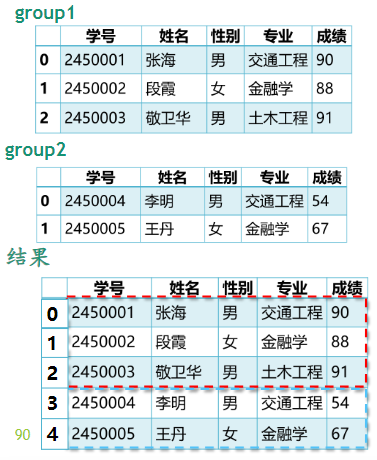
scores=pd.concat([group1,group2]) # 默认axis=0
print(scores)
同理,轴向列堆叠(axis=1):
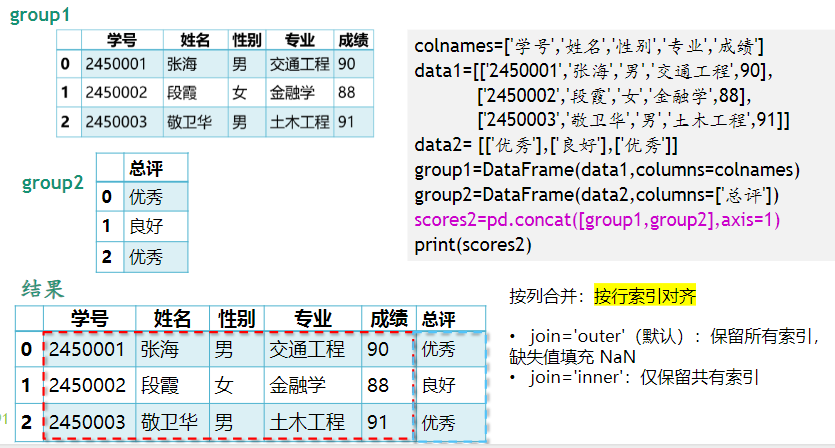
合并重叠数据
data1={'姓名':[np.nan, np.nan,'李明'], '性别':['男',np.nan,'男']}
index1=['2450001','2450002','2450004']
stu1 = DataFrame(data1,index=index1) data2={'姓名':['张海','段霞','敬卫华'], '性别':[np.nan,'女','男'], '成绩':[90,88,91]}
index2=['2450001','2450002','2450003']
stu2 = DataFrame(data2,index=index2)
result_data = stu1.combine_first(stu2)
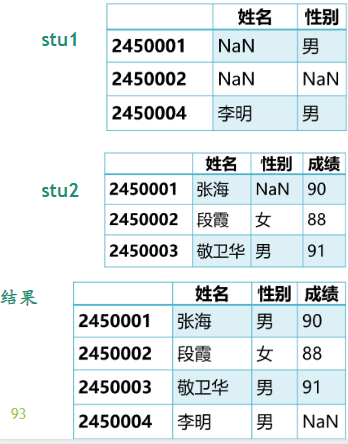
数据清洗
处理缺失数据
Pandas 常用 NaN 代表浮点或非浮点数据中的缺失值,Python 内置的 None 也会被当做缺失值来处理。
用 DataFrame/Series 对象的 isnull () 方法,返回形状相同的布尔型 DataFrame/Series 对象,查看缺失值是否存在,True 表示是缺失值。
• <对象名>. isnull (). any () 查看每列是否含有缺失值
• <对象名>. isnull (). any (axis = 1) 查看每行是否含有缺失值
• <对象名>. isnull (). all () 查看每列是否全为缺失值
• <对象名>. isnull (). all (axis=1) 查看每行是否全为缺失值,即 all (1)
处理缺失值方法:1)滤除缺失值 2) 填充缺失值
滤除缺失值:df.dropna(axis=0, how='any', thresh=None, inplace=False)
填充缺失值:df.fillna(value=None,method=None,axis=None,inplace=False)
去除重复数据
#检测那些行是重复行
is_dup = df.duplicated()
#删除重复行
result = df.drop_duplicates()
内容和格式的清洗
df.replace (to_replace, value, inplace, method)
第三章 数据统计分析_20250323, 页面 103
示例:将性别 male 替换为'男',female 替换为'女' ,将年龄-1 替换成 30 岁
patient_data.replace({'male':'男','female':'女'},inplace=True)
patient_data['年龄'].replace(-1,30,inplace=True)
将身高的单位统一成‘m
# 获取身高以cm为单位的行(布尔值),遇到缺失值默认返回
False rows_with_cm = patient_data['身高'].str.contains('cm',na=False)
#仅仅对含有cm的每一行,去掉后缀cm,转换为m
for i,row in patient_data[rows_with_cm].iterrows():
#使用迭代器
height =float(row['身高'][:-2])/100
#身高的值转换为float,并换算为m的值
patient_data.loc[i,'身高'] = f'{height:.2f}' +'m'
# 该列值带上单位'm' # 去掉身高数据中的单位
patient_data['身高']=patient_data['身高'].str[:-1]
# 将该列重命名为"身高/m"
patient_data.rename(columns={'身高':'身高/m'},inplace=True)
数据转换
用函数变换
•Numpy的元素级数组方法可用于Pandas对象,如 np.abs(df),np.sqrt(df),np.log(df)
• DataFrame/Series对象的apply(f)方法将函数f应用到DataFrame对象的各列或行形成的一维数组上。axis为0时,作用到每一列上;axis为1时,作用到每一行上。axis默认为0。
• DataFrame对象的applymap(f)方法将函数f应用到DataFrame对象的每个元素上。
• Series对象的 map(dict) 方法对 Series 中的每个元素应用映射规则,可以是一个函数,也可以是一个字典或Series。如果传入的是函数,则对每个元素执行该函数的运算。如果传入的是字典或另一个Series,则根据“键-值”对进行替换。
示例:函数变换
from pandas import DataFrame
marks=DataFrame({'高数':[90,85,85,90],'英语':[85,92,87,95], '程序设计':[90,80,82,97]}, index=['张楠','吴京','李海明','王华'])
def f(x):
return x+2
marks=marks.applymap(f)
marks['程序设计']=marks['程序设计'].apply(lambda x:"优" if x>=90 else "良") print(marks)
示例:map 映射
iris_data=pd.read_csv('iris_6.csv') # 读取 6朵鸢尾花数据
# 1.先构造映射字典,键是原本类别名称,值是对应的数字编码
target_value={"Iris-setosa":1,"Iris-versicolor":2,"Iris-virginica":3}
# 2. 然后,在target列上应用map函数:
iris_data['target']=iris_data['target'].map(target_value)
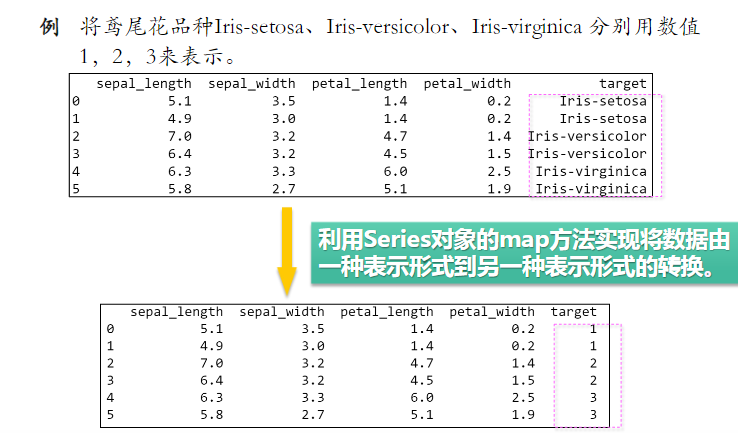
离散化(针对连续性数据)
将原本连续的数值特征划分为若干个区间(面元),并用区间标签来代替原有数值。
students=pd.read_csv('students_info.csv',header=0,encoding='gbk')
bins=[0,60,70,80,90,101]
names=['不及格','及格','中','良','优']
students['等级']=pd.cut(students['成绩'],bins,labels=names,right=False) print(students)
主要实现的函数:
pd.cut (X, bins, right= True, labels=None, …)离散化
第三章 数据统计分析_20250323, 页面 114
pd.qcut (x, q, labels=None, retbins=False)
第三章 数据统计分析_20250323, 页面 115
按照样本的分位数来分箱,自动计算分位点,把数据分割成若干区间,并保证每个区间样本数大致相同(等频划分);或者按照自定义的分位数列表来分箱,不一定等频。
哑变量矩阵编码分类特征(针对分类特征)
One-hot 编码为哑变量矩阵-适用于无序的分类特征:性别城市等
dummies=pd.get_dummies(data['ages'],prefix='age', dtype='uint8')
# 针对 ages 列里出现的每一种分类(如 '少年', '青年', '中年'),创建一 个形如 age_少年, age_青年, age_中年 的新列。
示例:鸢尾花数据
iris_data=pd.read_csv(r'iris_6.csv')
dummies=pd.get_dummies(iris_data['target']) # 对target列进行one-hot编码
data = iris_data.iloc[:,:-1] # 不含target列
data_with_dummy=pd.concat([data,dummies],axis=1,dtype='uint8') # 合并
data_with_dummy=data.join(dummies)# 合并方式2
数据排序
DataFrame 对象既可以按照值排序,也可以按照索引排序
1)df. sort_values (by,[参数列表]) 根据某列或多列的值进行排序 • by:指定排序的关键列或列列表,不可缺省,列名字符串或列名组成的列表。
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False,…)
• ascending:指定排序方式,True 为升序,False 为降序。或为一个布尔列表与 by 列表对应。 • kind:指定排序算法,值可取“quicksort”、“mergesort”或“heapsort”。 • na_position:缺失值(NaN)排在开头 (‘first’) 还是末尾 (‘last’)。
2)df. sort_index ([参数列表]) 根据行索引或列索引进行排序 • axis:axis=0 按行索引排序;axis=1 按列索引排序。
DataFrame.sort_index(axis=0, ascending=True,inplace=False, kind='quicksort', na_position='last',...)
数据统计分析
常见统计数据
| 统计量 | 描述 | 计算方法 |
|---|---|---|
| 均值(mean) | 数据的平均值,所有观测值的总和除以观测值的个数 | df.mean() 或 np.mean(arr) |
| 中位数(median) | 将数据排序后处于中间位置的值 | df.median() 或 np.median(arr) |
| 众数(mode) | 数据中出现频率最高的值 | df.mode() |
| 最大值(max) | 数据中的最大值 | df.max() 或 np.max(arr) |
| 最小值(min) | 数据中的最小值 | df.min() 或 np.min(arr) |
| 范围(range) | 最大值与最小值之差 | df.max() - df.min() |
| 方差(variance) | 衡量数据的离散程度,数据与均值差的平方和的平均值 | df.var() 或 np.var(arr) |
| 标准差(std) | 方差的平方根,以原始单位表示数据的离散程度 | df.std() 或 np.std(arr) |
| 四分位数(quantile) | 将数据分为四等份的位置的值,常用Q1(25%)、Q2(50%)、Q3(75%) | df.quantile([0.25, 0.5, 0.75]) |
| 计数(count) | 数据中非缺失值的数量 | df.count() |
| 总和(sum) | 所有数据的总和 | df.sum() 或 np.sum(arr) |
| 偏度(skewness) | 描述数据分布的不对称程度 | df.skew() |
| 峰度(kurtosis) | 描述数据分布的峰态,反映分布曲线的陡峭程度 | df.kurt() |
| 协方差(covariance) | 衡量两个变量共同变化的程度 | df.cov() |
| 相关系数(correlation) | 衡量两个变量之间线性关系的强度和方向 | df.corr() |
df.describe() 方法可以生成 dataframe 对象各列的统计信息摘要 |
分组和聚合
分组
df.groupby():根据指定的列 (或多列) 把 DataFrame 对象拆分为多个分组,返回一个 GroupBy 对象,包含分组相关信息。
students=pd.read_csv('students_info.csv',header=0,encoding='gbk')
grouped=students.groupby(students [‘专业’])#按照某个列(如专业)分组
grouped1=students.groupby([‘专业’,‘性别’]) #按照多个列分组
查看分组信息:
for name,group in grouped:
print(name) #分组名
print(group) #该分组对应的DataFrame
聚合
聚合方法:常用统计方法、agg (自定义函数) 方法、apply (函数) 方法
常用统计方法
作用于分组对象,实现数据聚合
先分组,然后调用分组对象的聚合方法,将结果聚合。
#单列聚合
grouped[‘成绩’].mean() #对”成绩”这一列做分组后的平均值
#多列聚合
grouped[[‘身高/m’, ‘体重/kg’]].max() #同时对”身高”、“体重”列求max
其他常见聚合函数:sum()加和;count()计数(非 NaN 值);median()中位数; std()标准差;var() 方差;min()最小值; max() 最大值
使用 agg () 方法(自定义函数)聚合
如果想对同一列做多个聚合,或使用自定义函数 (当 pandas 的统计方法无法满足聚合需求),可用 agg () 方法。返回一个 DataFrame/Series 对象
# 对“成绩”做多个统计:mean、max,显示为两列
grouped['成绩'].agg(['mean','max'])
def f(arr):
return arr.max()-arr.min() #计算成绩的极差
grouped['成绩'].agg(f) # 对单列聚合
#分组上同时应用多个聚合函数
grouped['成绩'].agg(['mean','min','max',f ])
#自定义列别名
grouped['成绩'].agg([('平均分','mean'),('最低分', 'min'), ('最高分','max'),('最高分-最低分',f)])
# 多列使用不同函数
grouped.agg({'身高/m':'mean','体重/kg':'min','成绩':f})
分组上同时应用多个聚合函数,将多个函数名放入列表中。注意自定义函数名不加引号!
在 agg 的参数中,用(自定义列名,函数名)组成的元组形式取代函数名,可以在结果中自定义列名
在 agg 的参数中,用{列名:函数名}组成的字典形式,表示对不同的列使用不同的函数
使用 apply () 方法聚合数据
与 agg ( ) 方法基本相同,在某些场景下,想对每组数据执行更复杂或非聚合型操作,可使用 apply ()
不同:agg ( ) 方法可以对不同的列应用不同的函数,apply ( ) 方法只能对一个或多个列应用同一个函数
grouped.apply('mean') #计算均值
grouped[‘成绩’].apply(‘mean’) #计算某列的均值
def func(sub_df):
return sub_df['成绩'].max() - sub_df['成绩'].min()
range_res = grouped.apply(func)
数据透视表
数据透视表
数据透视表可在行、列、值三个方向上进行分组聚合,把多维数据整理成一个二维表,从而更直观地查看不同分类组合下的统计指标。
tudents=pd.read_csv('students_info.csv',header=0,encoding='gbk')
students.pivot_table('成绩',index='专业',columns='性别', aggfunc='mean',margins=True, margins_name='合计',fill_value=0)
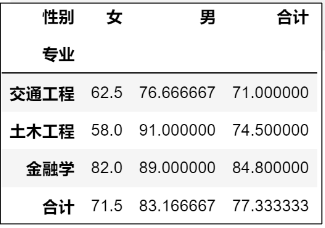
df.pivot_table(…),根据一个或多个键对数据进行聚合,生成数据透视表(DataFrame对象)
交叉表
pd.crosstab (index, columns,…)计算两个 (或多个) 因子的简单交叉表
相关分析
相关性是指两个变量之间的关联程度。如果当一个变量变化时,另一个变量也随之发生有规律的变化,就说明这两个变量之间存在一定相关关系
- 正相关:两个变量之间有一种同向变化的关系。当一个变量增大时,另一个变量也倾向于增大;当一个变量减小时,另一个变量也倾向于减小。如身高与体重。
- 负相关:表示两个变量之间有一种反向变化的关系。当一个变量增加时,另一个变量倾向于减少。如车速与所需行驶时间。
- 不相关:两个变量之间没有明显的关联或趋势,即一个变量的变化对另一变量没有明显影响,那么这两个变量不相关。如姓名与成绩
两个连续变量线性相关强度和方向,常用皮尔逊相关系数来衡量
① 𝜌𝜌的值介于-1 和+1 之间 ② 一般而言, 𝜌>0,正相关,越接近 1,正相关越强 𝜌<0,负相关,越接近-1,负相关越强 𝜌=0,不相关或极弱相关,基本无线性关系
相关矩阵:
一个方阵,其中每个元素表示两个变量之间的相关系数 •
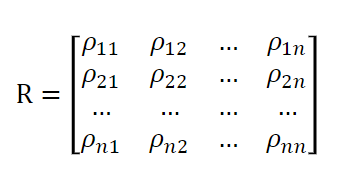
Pandas 中计算变量相关性的方法:stock['招商银行']. corr (stock['万科 A']) 或 stock.招商银行.corr (stock. 万科 A) 求相关系数矩阵: stock.corr()`
PPT-4
数据可视化部分,Matplotlib
一个图表的组成:
1.容器层:最外层,组织和管理所有显示元素:Canvas\Figure\Axes
2. 辅助显示层:专门放置辅助解释信息的组件,如坐标轴、刻度、标签、图例等。
3. 图像层:对应于数据的实际绘制部分,也就是展示主要数据内容的图层。
图表的基本元素:
每个 axes 中又有:坐标轴(x 轴、y 轴)刻度(ticks)与刻度标签(tick labels)网格(grid lines)图例(legend)标题(title)及轴标签( xlabel、ylabel)
例题
引例-天气数据可视化
折线图应用
例 4.2 绘制常用激活函数的曲线图
金融案例
绘制心形曲线
了解海洋中某观测站在 2024 一年中(12 个月)的平均浪高(单位: 米),通过柱状图对比不同月份的浪高水平。
地球物理案例
饼状图的代码
例 4.5 (1) 鸢尾花的分类散点图
医学案例——散点图及回归估计
例 4.6 用直方图分别显示泰坦尼克号上乘客的性别和年龄分布情况
图像处理的灰度分析、阈值分割、亮度/对比度评估
例 4.7:分析学生成绩(读文件数据)
营养学案例——绘制箱型图
地理环境案例
例 4.10 用 scatterplot 绘制鸢尾花的散点图
例 4.12 用 relplot 绘制数据集 fmri.Csv (功能性磁共振成像) 的折线图
例 4.11 用 relplot 绘制鸢尾花的散点图
【例 4.13】绘制鸢尾花花萼长度的密度图
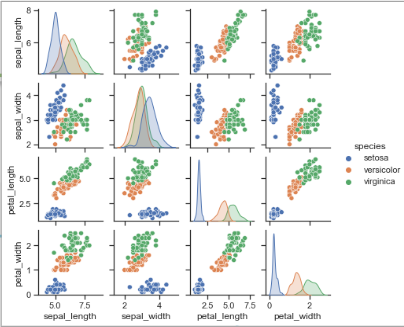
【例 4.14】绘制鸢尾花数据的对图
【例 4.15】绘制小费数据集(tips. Csv)中 tips 特征数据的对图
【例 4.16】计算红酒数据集(wine. Csv)的相关系数矩阵,绘制相应的热力图
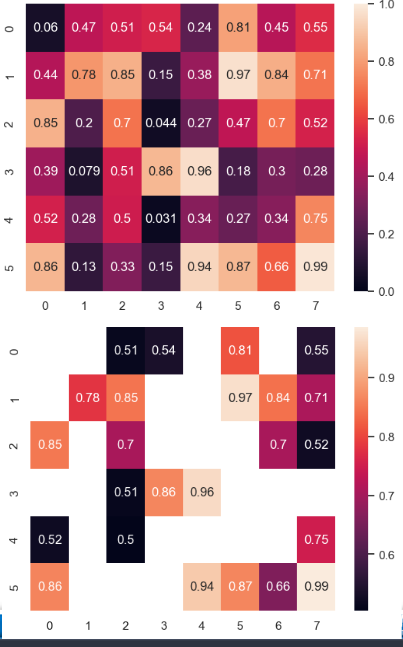
【例 4.17】随机生成 6×8 的矩阵,绘制带有上下限或者隐藏部分范围的热力图
例 4.18 依据 flights. Csv 数据集,绘制航班数据热力图
综合案例 1—空气质量分析
Matplot 的基本内容共识
创建 Figure 和 Axes
1)自动创建
调用 plt.plot (...) 等绘图函数时,如果当前没有任何激活的 Figure 或 Axes, Matplotlib 会自动创建默认大小的 Figure(画布容器)和其中的 Axes(坐标系),然后进行绘制
例如:根据下列操作,其实已经创建好了
import matplotlib.pyplot as plt
plt.plot((3,6))
2)手动创建
通过 plt.figure (figsize=(W, H), dpi=DPI) 来创建 Figure 对象后,如果没有显式地创建 Axes,调用 plt.plot (...) 时会自动在这个 Figure 中生成一个 Axes
例如:
import matplotlib.pyplot as plt
plt.figure(figsize=(6,4),dpi=72) #Figure为6英寸宽*4英寸高,分辨率为72像素/英寸
plt.plot((3,6)) #绘制一条从顶点(0,3)到顶点(1,6)的直线
最终计算图像像素大小:6 x72 像素宽,4 x 72 像素高
通过 fig, ax = plt.subplots () 同时创建 Figure 和 Axes 后,再在 Axes 上调用 plt.plot (...)
如下:
#fig 是 Figure,ax 是 Axes;在 Axes 上调用 ax.plot(...) 绘制图形
fig, ax = plt.subplots(figsize=(6,4), dpi=72)
ax.plot([3,6])
plt.show()
绘图区函数:
figure():创建一个 Figure 对象
Figure ([num=None, figsize=None, dpi=None, facecolor=None……, kwargs]) 可以指定一些全局属性,如 figsize(图表大小)、dpi(分辨率)、facecolor(背景色)等
如:plt.figure (figsize=(6,6), facecolor=‘g')
注意:后续需要在此对象中创建 Axes(子图)才能进行实际数据绘制。如果未手动创建 Axes,Matplotlib 会在需要时自动创建一个默认的 Axes。
axes():显式创建并返回一个新的 Axes 对象到当前的 Figure 中
创建子绘图区
subplot( ):plt.subplot(nrows, ncols, index, **kwargs)
在 Figure 内,按照网格布局 (nrows 行*ncols 列),创建/激活某一个 Axes (子绘图区),其索引为 index (先按行,再按列)
plt.subplot(1,1,1) #在当前Figure中建立1行*1列的网格,选中并绘制在第1个子绘图区
plt.subplot(232) #有2行3列共6个子绘图区,此时切换/创建并激活第2个,并在此位置绘图
# 如果nrows、ncols和index都小于10缩写为一个整数:
subplot(323) #等价于subplot(3,2,3)
add_subplot:add_subplot(nrows, ncols, index[, **kwargs])
用于在已有的特定 Figure 对象上添加子绘图区,返回的是创建或获取的 Axes 对象
import matplotlib.pyplot as plt
import numpy as np fig1=plt.figure( ) #创建一个Figure对象
fig1.add_subplot(221) #定位到第1个Axes
x=np.random.randint(0,100,50) #随机生成50个坐标点(x,y)
y=np.random.normal(0,100,50) plt.scatter(x,y,c=‘r’) #绘制到当前Axes上
ax4=fig1.add_subplot(224) #定位并获取第4个Axes
ax4.plot((5,3,5),c='b',marker='D') #绘制蓝色折线并输出标记
add_subplot 可以用于图形嵌套:可以在任何时刻向已有的 fig 中添加新的 Axes
示例如下:
import matplotlib.pyplot as plt import numpy as np fig1=plt.figure( ) #创建一个Figure对象
ax1=fig1.add_subplot(111) #定位并获取第1个
x=np.random.randint(0,100,50) #随机生成50个坐标点(x,y)
y=np.random.normal(0,100,50)
ax1.scatter(x,y,c='r') #输出随机生成的坐标点
ax2=fig1.add_subplot(331) #分成3*3个子绘图区,获取第1个
ax2.plot((5,3,5),c='b',marker='D') #绘制蓝色折线并输出标记
subplots()函数plt.subplots(nrows=1, ncols=1, figsize=None, **kwargs)
一次性创建一个 figure 对象和对应网格布局的所有 Axes,返回(fig, axes)
用法如下:
fig,ax = plt.subplots(nrows=2,ncols=3,figsize=(6,4),dpi=72)
plt.subplots_adjust(wspace=0.3,hspace=0.3) #调整子绘图区之间的间隔
ax[0][1].plot((5),‘r^’) #绘制一个红色三角标记
ax[1][2].plot((3,8),'g') #绘制一条绿色线条
返回的 ax 是一个 NumPy 数组 (当 nrows、ncols>1) 或单个 Axes 对象 (当 nrows=1, ncols=1)
当行数与列数值均大于 1 时,用 ax[i][j]访问;
当行数或列数只有一个值等于 1 时,用 ax[i]访问;
当行数与列数值均等于 1 时,用 plt 或 ax 访问;
常用图表函数
| 函数 | 描述 |
|---|---|
| plt.plot(x, y, color, linewidth, linestyle, label) | 根据(x,y)坐标绘制直线或曲线 |
| plt.boxplot(data, label) | 绘制一个箱型图 |
| plt.bar(x, height, width, bottom, *, align='center', **kwargs) | 绘制一个条形图(即柱状图) |
| plt.barh(y, width, height, left, *, align='center', **kwargs) | 绘制一个横向条形图 |
| plt.polar(theta, r) | 绘制极坐标图 |
| plt.pie(data, explode) | 绘制饼图 |
| plt.scatter(x, y) | 绘制散点图 |
| plt.hist(x, bins, normed) | 绘制直方图 |
| plt.contour(X, Y, Z, N) | 绘制等高线 |
坐标轴设置函数
| 函数 | 描述 |
|---|---|
| plt.axis() | 显示当前坐标轴刻度的取值范围 |
| plt.axes() | 显示子绘图区 |
| plt.xlim(xmin=1, xmax=5) | 设置X轴刻度取值范围为[1,5] |
| plt.ylim(ymin=3, ymax=6) | 设置Y轴刻度取值范围为[3,6] |
| plt.xscale(scale) | 设置X轴缩放,scale的取值['linear' | 'log' | 'logit' | 'symlog'] |
| plt.yscale(scale) | 设置Y轴缩放 |
| plt.autoscale() | 自动缩放轴视图的数据 |
| plt.text(x, y, s, fontdic, withdash) | 在指定位置添加注释文本 |
| plt.grid(True/False) | 是否显示绘图网格 |
标签设置函数
| 函数 | 描述 |
|---|---|
| plt.title("TITLE", loc='right') | 设置图表的标题,loc: |
| plt.xlabel("水平轴标题") | 设置X轴的标题 |
| plt.ylabel("垂直轴标题") | 设置Y轴的标题 |
| plt.legend(loc='upper right') | 在指定位置显示图例,一般在绘图函数中用label参数指定图例的文本内容 |
| plt.xticks() | 设置X轴的刻度范围及显示标签 |
| plt.yticks() | 设置Y轴的刻度范围及显示标签 |
绘制二维图表
绘制线条
plot( ):用于绘制线条和标记,不仅可以绘制折线图、曲线图,还可以制作出类似散点图的效果。 Plot 函数的使用形式为:plt.plot([x],y, [fmt],**kwargs)
参数说明:
① x 和 y 通常是列表或元组等序列,x 中存储所有顶点的 x 坐标序列,y 中存储所有顶点的 y 坐标序列,其中参数 x 可以缺省,缺省值为列表[0, 1, 2, …, n-1]。
② 参数 fmt 是一个字符串变量,用于定义图表的基本属性,如颜色(color)、标记(marker)、线型(linestyle)等。如:plt.Plot ([2,3],[5,7], 'bD: ', linewidth=5)
③ kwargs 是一个关键字参数,用于接收 0 个或多个由属性与属性值组成的键值对。若颜色属性赋值为"green"、"black"等单词形式,则不能用 fmt 参数来组合赋值,必须对单个颜色属性赋值。如:plt.Plot ([2,3],[5,7], color='blue', marker='D', linestyle =': ', linewidth=5)
至于线条的类型和线条的标记可见:第四章 数据可视化-2025408, 页面 25
柱状图
plt.bar(x,height,width=0.8,bottom=None,……,**kwargs,)
参数说明:① x 表示 x 坐标 ②height 表示柱状图的高度,也就是 y 坐标值, ③width 表示柱状图的宽度,取值在 0~1 之间,默认为 0.8 ④bottom 柱状图的起始位置,也就是 y 轴的起始坐标, ⑤align 柱状图的中心位置,"center","lege"边缘 ⑥orientation 柱状图是竖直还是水平,竖直 : "vertical" ,水平条 : "horizontal"
并列柱状图请看地物例子:
基本思想是增加一个 barW 来进行偏移,利用一个 for 循环画出不同种类的 bar
堆叠柱状图:
利用 bar 图的参数,bottom(底部高度,设置为前一个的高度,就会在这个基础上画,然后就可以堆叠了)
饼状图
plt.pie(x,explode=None)
参数说明:① x:数组或列表,用于绘制饼图的数据,表示每个扇形的面积。 ②explode:数组,表示各个扇形之间的间隔,默认值为 0。 ③labels:列表,各个扇形的标签,默认值为 None。 ④colors:数组,表示各个扇形的颜色,默认值为 None。 ⑤autopct:设置饼图内各个扇形百分比显示格式,%d\ 一位小数百分比, %0.2 f%% 两位小数百分比
散点图
散点图是一种用于研究变量之间关系的图表
plt.scatter(x, y, s=None, c=None, marker=None, cmap=None,**kwargs)
参数说明:① x,y:长度相同,即将绘制散点图的数据点,输入数据。 ②s:点的大小,默认 20,也可以是个数组,数组每个参数为对应点的大小。 ③c:点的颜色,默认蓝色 'b',也可以是个 RGB 或 RGBA 二维行数组。 ④marker:点的样式,默认小圆圈 'o'。 ⑤cmap:Colormap,默认 None,标量或者是一个 colormap 的名字,只有 c 是一个浮点数数组的时才使用。如果没有申明就是 image. cmap。
直方图
ax[1].hist(dt['age'], bins=15,color='salmon',edgecolor='black')
Bins 决定了直方图如何将 x 轴拆分成若干区间,并在每个区间统计频次
• 若 bins 是单个整数 n ,则自动从 (min (data) .. Max (data)) 分 n 段;
• 若 bins 是一组数,则是分箱边界,直方图有 len (bins)-1 个柱;
参数说明: ① x 是一个列表或元组序列,直接存放原始数据序列。 ② bins 参数指定直方图条形的个数,对应原始数据的统计类别个数,默认值为 10,每个条形图的高度对应当前类别的统计结果。 ③ range 参数指定直方图在 X 轴上数值的显示范围。 ④ rwidth 参数指定每个条形的宽度
箱型图
Plt.Boxplot (x,**kwargs) (Matplotlib 提供)
DataFrame.Boxplot (...)(pandas 提供)
参数说明: ① x 表示箱型图的数据
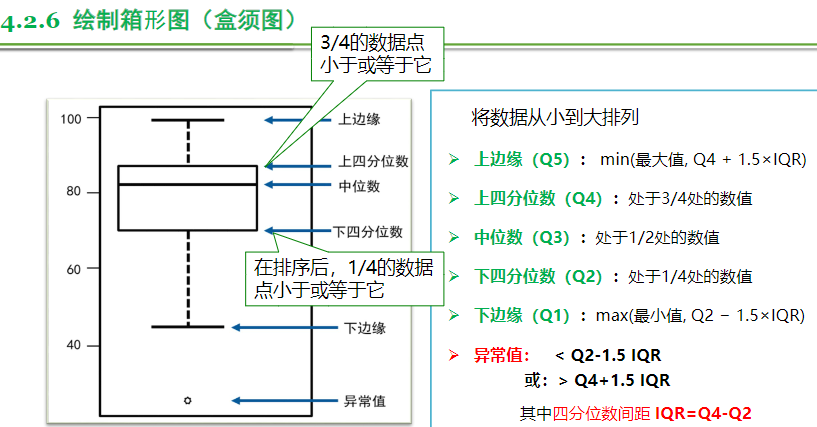
绘制三维表格
三维图表基础
首先正确显示三维绘图和坐标系
方法一:显示使用 Axes 3D
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig,auto_add_to_figure=False)
fig.add_axes(ax)
plt.show()
方法二:直接使用 projection=‘3d’
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 或等价的:
ax = plt.axes(projection='3d')
方法 2 更简洁,推荐
import matplotlib.pyplot as plt
import numpy as np
fig=plt.figure()
ax = fig.add_subplot(projection='3d')
x=[0,1]; y=[0,1]
X,Y =np.meshgrid(x,y) #X为array([[0, 1],[0, 1]]),Y为array([[0, 0],[1, 1]])
Z= X*Y #Z为array([[0, 0],[0, 1]])
ax.set_xticks([0,0.5,1]);ax.set_yticks([0,0.5,1]); ax.set_zticks([0,0.5,1])
ax.scatter(X,Y,Z)
np.meshgrid(x,y): 将 x、y 两个一维坐标转换成网格坐标 X、Y X[i, j] 与 Y[i, j] 对应网格中第 i 行、第 j 列的点
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(12,5)) #创建全局绘图区
ax1 = fig.add_subplot(121,projection='3d') #添加三维子绘图区1
ax1.plot((0,3),(0,3),(0,3),ls=‘--’,lw=5) #绘制三维线条(0,0,0)到(3,3,3)
ax2 = fig.add_subplot(122,projection='3d') #添加三维子绘图区2
ax2.plot((0,3,0,0,0,0,0,3),(0,3,3,3,0,3,3,3),(0,0,3,0,0,3,0,0),c='r',marker="D") #绘制三维折线与标记
plt.show()
for i in range(3): #代表3行数据(3年)
ax.bar(xs,dtA.values[i,1:5],ys[i],zdir='y',width=width)
ax.bar(xs+width,dtB.values[i,1:5],ys[i],zdir='y',width=width)
ax.set_zlabel('销售额(万元)') #设置Z轴标签
plt.title("2018~2020年各季度销售额") #设置图表标题
plt.xticks([1,2,3,4],dtA.columns[1:]) #设置X轴刻度的显示标记
plt.yticks([2018,2019,2020],dtA["年份"]) #设置Y轴刻度的显示标记
plt.show()
Seaborn 库
Seaborn 库参数设置
sns.set_style():仅设置主题(网格/背景)
sns.set_context():调上下文(字体大小、粗细等)
sns.set_palette():颜色序列
sns.set():最简便,一次性配置 style、context、palette、font 等
Seaborn 有五个预设好的主题: darkgrid (默认), whitegrid,dark,white,和 ticks
Seaborn 常用数据函数等
| 类别 | 图形 | 方法 | 参数说明 |
|---|---|---|---|
| 趋势图 | 点图 | sns.pointplot() |
data:DataFrame数据源x, y:指定数据列名hue:分类变量,用不同颜色区分palette:配色方案markers:点的形状ci:置信区间 |
| 折线图 | sns.lineplot() |
data:DataFrame数据源x, y:指定数据列名hue:分类变量,用不同颜色区分style:线型分类变量markers:是否显示标记dashes:是否使用虚线 |
|
| 关系图 | 散点图和折线图 | sns.relplot() |
data:DataFrame数据源x, y:指定数据列名hue:分类变量,映射到颜色size:数值变量,映射到点大小style:分类变量,映射到标记形状row, col:分面变量kind:'scatter'或'line',指定图形类型 |
| 散点图 | sns.scatterplot() |
data:DataFrame数据源x, y:指定数据列名hue:分类变量,映射到颜色size:数值变量,映射到点大小style:分类变量,映射到标记形状alpha:透明度 |
|
| 线性回归图 | sns.regplot() |
data:DataFrame数据源x, y:指定数据列名scatter:是否显示散点fit_reg:是否拟合回归线ci:置信区间order:多项式回归的阶数 |
|
| 回归图 | sns.lmplot() |
data:DataFrame数据源x, y:指定数据列名hue:分类变量col, row:分面变量order:多项式回归的阶数ci:置信区间scatter_kws:散点参数 |
|
| 分类散点图 | sns.swarmplot() |
data:DataFrame数据源x, y:指定数据列名hue:分类变量dodge:是否将点分开orient:方向,'v'或'h'size:点的大小 |
|
| 对图 | sns.pairplot() |
data:DataFrame数据源hue:分类变量kind:非对角线图形类型,'scatter'或'reg'diag_kind:对角线图形类型,'hist'或'kde'corner:是否只显示下三角markers:点的形状 |
|
| 条形图 | sns.barplot() |
data:DataFrame数据源x, y:指定数据列名hue:分类变量palette:配色方案ci:置信区间estimator:统计函数,默认为平均值 |
|
| 热力图 | sns.heatmap() |
data:矩阵或DataFrameannot:是否显示数值fmt:数值格式化字符串cmap:颜色映射vmin, vmax:颜色范围square:是否使用方形单元格mask:布尔数组,用于遮罩部分数据 |
|
| 分布图 | 直方图 | sns.displot() |
data:DataFrame数据源x, y:指定数据列名hue:分类变量kind:图形类型,'hist'、'kde'或'ecdf'bins:直方图的分箱数kde:是否叠加核密度估计height:图形高度 |
| 密度图 | sns.kdeplot() |
data:DataFrame或数组x, y:指定数据列名hue:分类变量fill:是否填充曲线下方multiple:多条曲线的显示方式,'layer'或'stack'bw_adjust:带宽调整系数alpha:透明度 |
|
| 联合分布图 | sns.jointplot() |
data:DataFrame数据源x, y:指定数据列名hue:分类变量kind:图形类型,'scatter'、'kde'、'hex'等height:图形高度ratio:边缘图与联合图的比例space:图与图之间的间隔 |
Seaborn 的案例
scatterplot 散点图
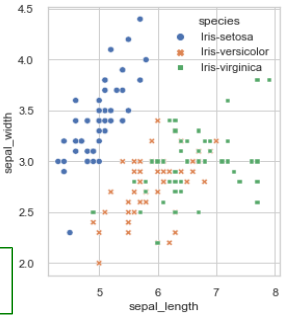
scatterplot 绘制鸢尾花的散点图:sns.scatterplot(data = iris, x="sepal_length", y="sepal_width",hue="species", style="species" )
- data 指定数据源的 DataFrame
- x 和 y 分别指定 X 轴和 Y 轴所使用的列名
- 绘制散点图,每一行数据对应一个散点
- hue 指示用不同的颜色分类显示数据点
- style 用分类变量映射到散点的形状
- size 可用数值列映射散点的大小
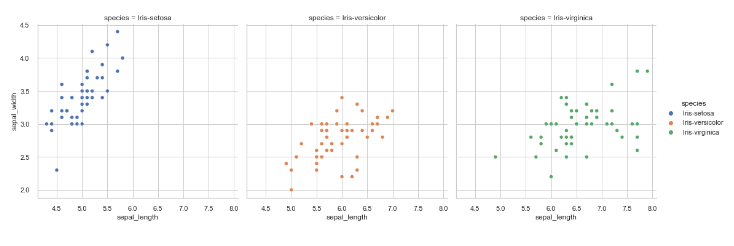
relplot 关系图
relplot 方法: 关系图—封装散点图和折线图
sns.relplot(data,x, y, hue, size, style, row, col, kind='scatter')
Data: 要绘图的 pandas DataFrame; x, y: 指定数值列名 hue: 分类列,映射到不同颜色 size: 数值列,映射到散点大小 (针对 kind='scatter') style: 分类列,映射到不同的散点形状/不同的线型 kind: ‘scatter’ (默认) 查看 (x, y) 之间分布;或‘line’查看 (x, y) 关系中的走向或趋势 row, col: 分面,按某分类变量分行/列布置子图
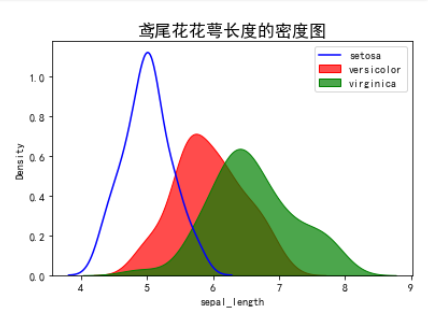
kdeplot 密度图
kdeplot 方法(密度图): kdeplot (x=None, *, y=None, shade=None, vertical=False)
① x 和 y 指定绘图的数据源 ② shade 指定密度曲线内是否填充阴影 ③ vertical 布尔类型,指定密度图的方向
Kdeplot是用于绘制核密度估计 (kernel density estimation, KDE) 的函数- KDE 通过对数据分布做平滑估计,绘制连续概率密度曲线 (1 D) 或等高线图 (2 D)
- 与直方图类似,都展示分布,但 KDE 更平滑地展现数据分布,有助于观察数据集中/峰谷位置
- 分布曲线上的每一个点都表示概率密度分布曲线下的每一块面积都是特定变量区间发生的概率
pairplot 对图
pairplot 方法 (对图): 用于分析数据集中所有特征对之间的关系
pairplot(data, kind, diag_kind, hue, palette,……)
参数说明: ① data 指定绘图数据源 ② kind 设置非对角线图形类别: scatter (散点) 或 reg (带回归线的散点图) ③ diag_kind 用于设置对角线上图形的类别: hist 或 kde(核密度估计) ④ hue 用于设置颜色 ⑤ palette 用于设置配色方案
heatmap 热力图
heatmap 方法(热力图):热力图用颜色映射数值大小,对一个矩阵或 2 D 数据进行可视化,把每个单元格的数值转换为不同色度或色彩深度。
heatmap(data, cmap, annot, fmt, ……):参数说明: ① data 指定数据源 ② cmap 指定色彩方案 ③ annot(注释)是否在每个方格里标注数据,默认为 False ④ fmt 指定数据显示的格式
- 适用于相关矩阵、混淆矩阵、或二维表格等情形,直观看出高低值的分布
- 常用于:在数据分析与特征工程中,将皮尔森相关系数矩阵可视化,
data=df.corr (),快速定位特征间的相关程度、哪些变量与目标有较强相关; - 在分类任务评估中,
data= confusion_matrix (y_true, y_pred),直观看出分类正确与否、错误类型分布; - 可视化透视表,
data= df. Pivot_table (), 展示行列组合下的数值分布